Smart Document Crawler
All’interno di Smart Document Access, è possibile configurare il crawler per l’indicizzazione dei contenuti di un sito web.
Il crawler opera in due fasi distinte: una prima fase di navigazione dei link, che mappa la struttura del sito senza estrarre contenuti, e una seconda fase di estrazione dei contenuti, che genera i documenti PDF indicizzati.
Attivazione e creazione della struttura
All’interno di una sottocartella già creata, selezionare l’opzione “Configura Smart Crawler”.
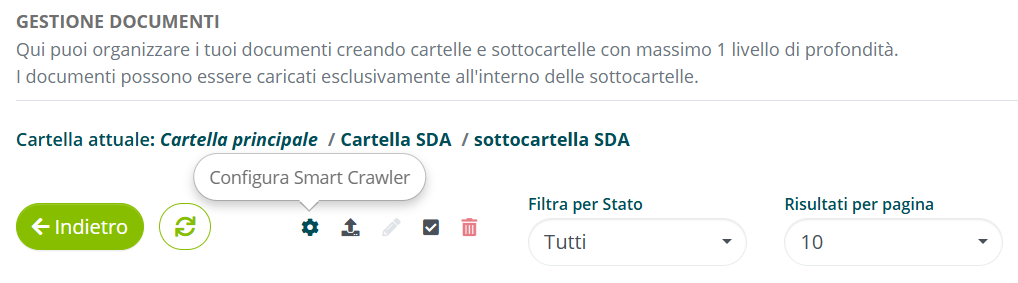
Attivare la spunta “Abilita su sottocartella”
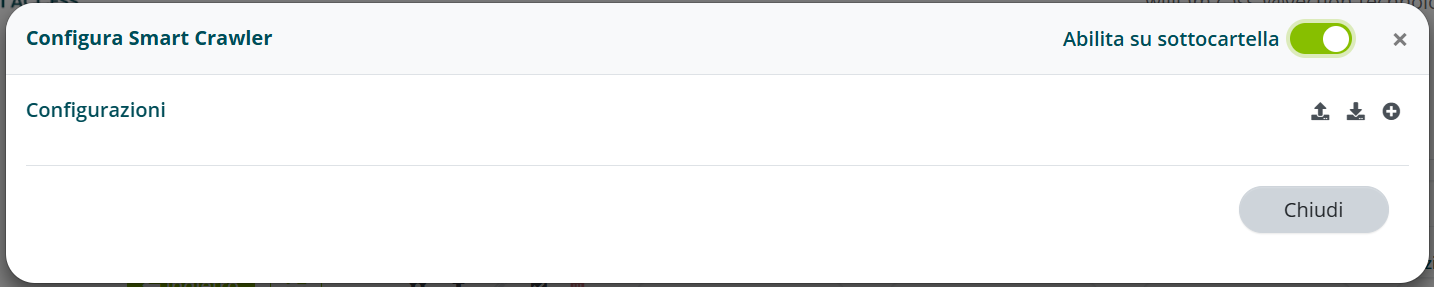
Selezionare “Aggiungi configurazione”

Assegnare un nome alla configurazione e selezionare “Salva”.
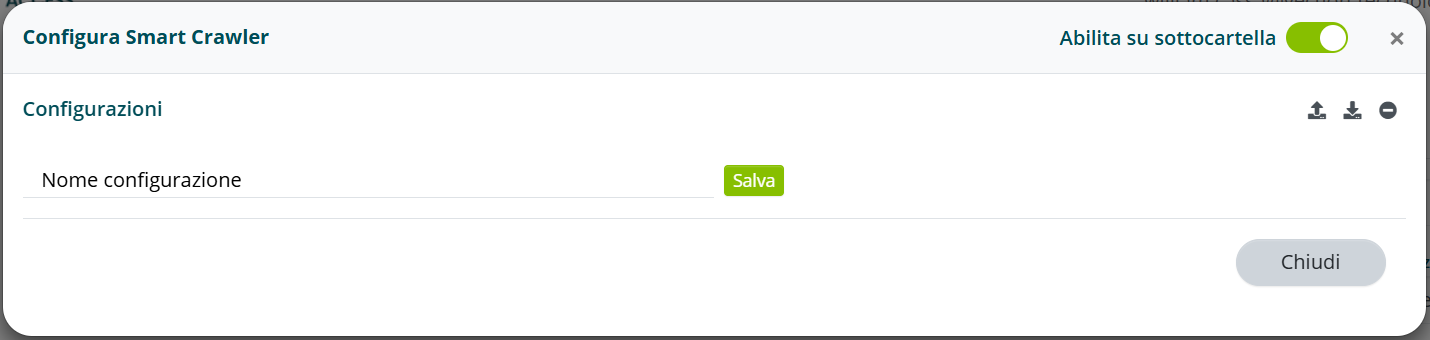
In questa fase è possibile importare configurazioni precedentemente scaricate oppure scaricare quelle già presenti.
Impostare il Crawler
Selezionando “Modifica campi” si accede alla configurazione del Crawler.
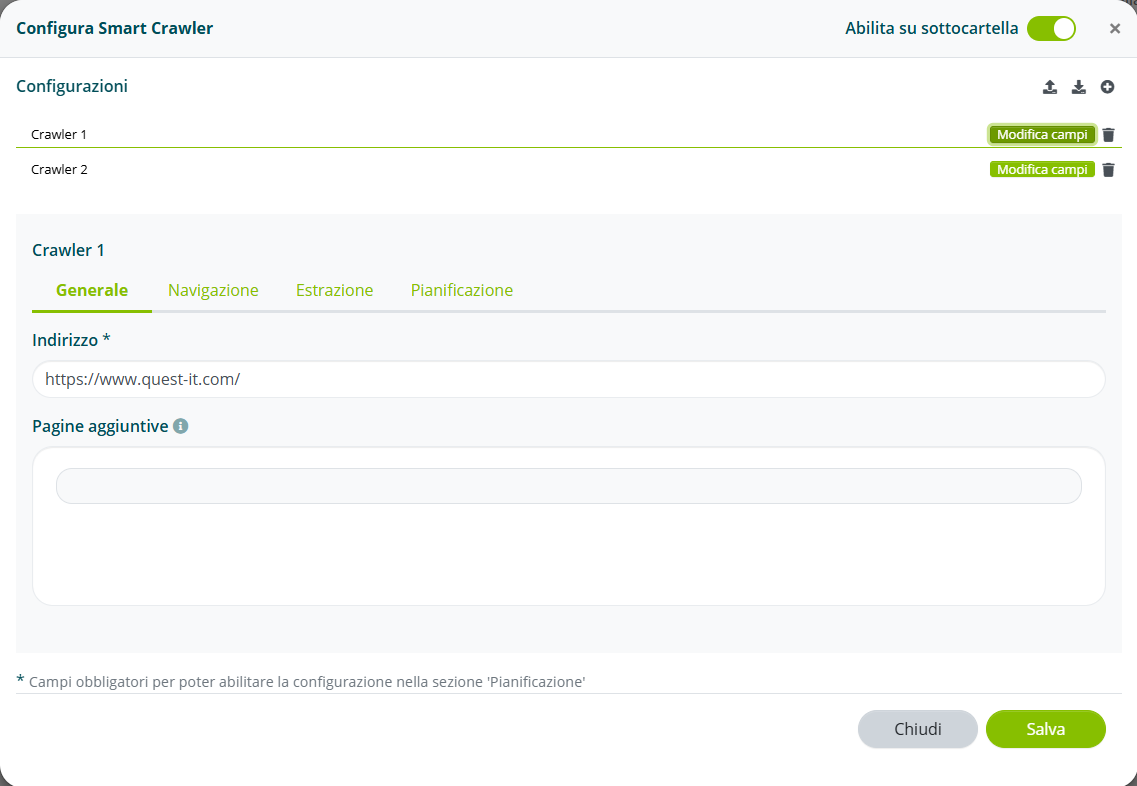
Generale
Inserire l’URL di partenza del sito nel campo “Indirizzo”.
Inserire altri URL in “Pagine aggiuntive” se necessario.
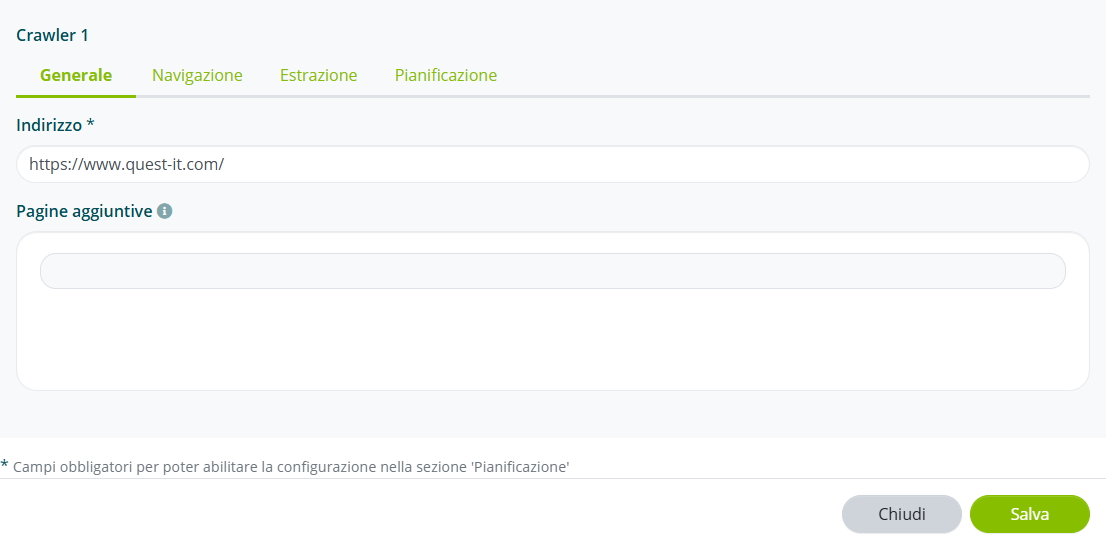
Navigazione
Abilitare l’opzione “Escludi i siti fuori dal dominio” per limitare la navigazione ai soli link interni al dominio principale.
Abilitare l’opzione “Includi documenti PDF, doc, docx” se si vogliono navigare anche i documenti allegati alle pagine web.
Nel campo “Indirizzi da includere” inserire l’elenco delle pagine del sito da navigare.
Nel campo “Indirizzi da escudere” inserire l’elenco delle pagine del sito da non navigare.
È possibile utilizzare espressioni regolari (regex) per indicare molteplici pagine.
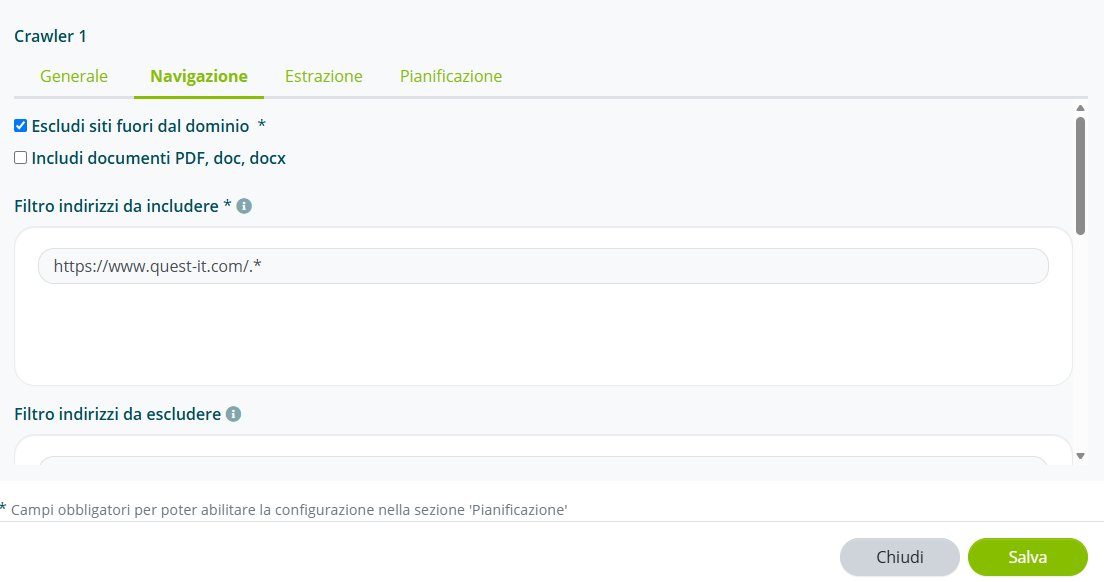
Impostare la profondità massima e il numero massimo di pagine da navigare.

Estrazione
Nella sezione “Estrazione” vengono configurate le regole che il Crawler seguirà per trasformare le pagine web in documentazione.
Nel campo “Filtro indirizzi da includere” inserire l’elenco delle pagine da estrarre e convertire in documentazione.
Le pagine da estrarre potrebbero coincidere con le pagine da navigare.
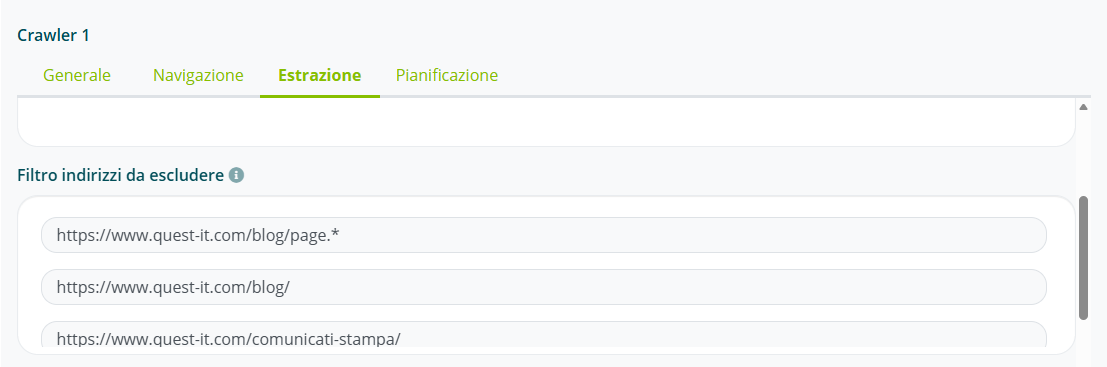
Nel campo “Filtro indirizzi da escludere” inserire l’elenco delle pagine da non estrarre.
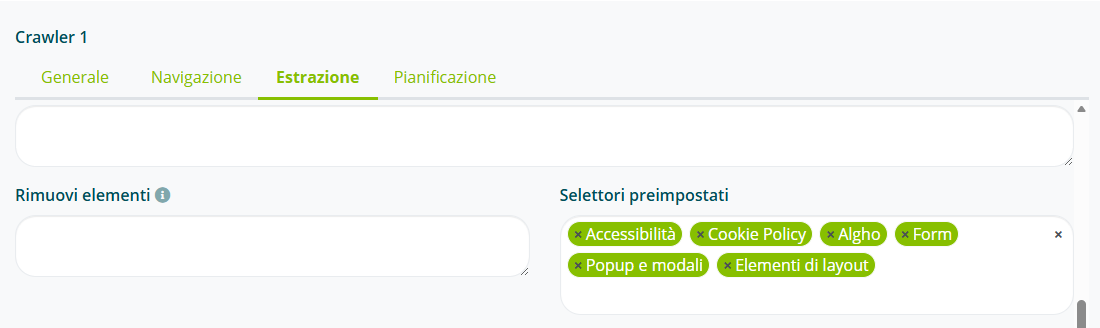
Aggiungere i selettori preimpostati nel campo “Rimuovi elementi”.
Gli elementi da rimuovere prima dell’estrazione possono anche essere indicati manualmente, specificando un selettore CSS, XPATH o compatibile con Puppeteer.
Pianificazione
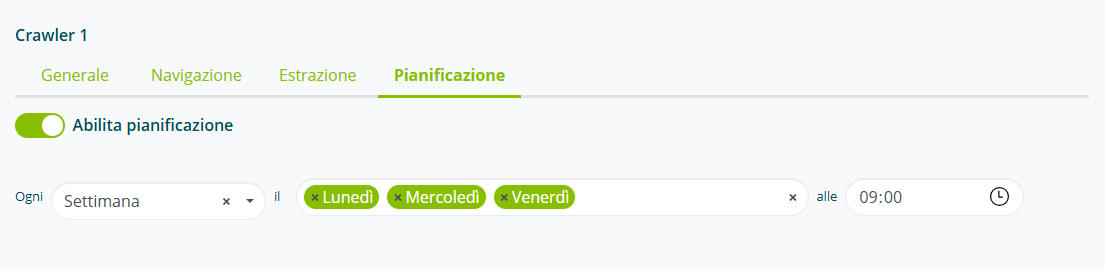
Selezionare “Abilita pianificazione” e stabilire la frequenza di esecuzione del Crawler (settimanale o mensile) e impostare il giorno e l’ora di partenza; è possibile impostare più giorni della settimana o del mese per l’esecuzione ripetuta.
Visualizzazione dei documenti
Per verificare i documenti PDF generati dal crawler, tornare all’interno della sottocartella in Smart Document Access.
L’elenco dei documenti indicizzati sarà disponibile nella sezione dedicata alla sottocartella configurata.
Ogni documento ha associato come “File origine” l’URL da cui è stato generato il documento.